Food conversions calculation¶
Food conversions are computed using a recursive search algorithm to link foods-as-eaten to modelled foods, possibly through intermediate conversion steps. For instance, if (unpeeled) apple and grapes are the modelled foods, the food-as-eaten apple pie contains peeled apple and raisins, peeled apple is linked to unpeeled apple, and raisins are dried grapes. Hence, for apple pie, there are two conversions, one to apple (with processing type ‘peeled’) and one to grapes (with processing type ‘dried’), each with its own conversion path of intermediate conversion steps.
Substance independent conversion¶
The current implementation of the food conversion algorithm can be run substance independent. The Find processing link (deprecated) is skipped from the algorithm (default = false) and is only retained for backwards compatibility reasons only (see Advanced, set to true). Processed foods are easily recognized in the food translation step and retrieving the processing factor that belong to a certain the processing type is done outside the algorithm. In fact, finding processing types with corresponding processing factors is not a task of the conversion algorithm: conversion is about converting food codes to other food codes.
When the processing step is skipped, there is no need to run the conversion algorithm on a substance basis. The only information that is needed is whether a food code is a modelled food or not (i.c. is there a concentration available or not). This information can be computed beforehand: for each substance all modelled foods are collected and supplied to the conversion algorithm in a common dictionary containing all modelled food codes. As soon as a food code is found in the dictionary, the conversion ends and the next food code is converted.
For each food-as-eaten, the food conversion algorithm recursively builds up the conversion paths using the following procedure:
Substance independent conversion: the conversion algorithm is substance independent. Check whether the current food is a modelled food. If successful, the food has been found, and the current search stops.
Check whether the current food translates to one or more foods through composition or read-across. Identify any processing types.
Food recipe link: try to find food translations for the current food (i.e., the ingredients of a composite food). This may result in one or more food codes for ingredients, and the iterative algorithm will proceed with each of the ingredient food codes in turn. Simultaneously check, whether the current food is a processed food or not. If so, determine the processing type or facets.
TDS food sample composition link: try to find the code in the TDSFoodSampleCompositions table (column idFood), a default translation proportion of 100% is assumed. The iterative algorithm will proceed with a TDS food (column idTDSFood) sample.
Read-across link: try to find a food extrapolation rule for the current food, a default translation proportion of 100% for ‘idToFood’ is assumed.
Note that in the food recipe link processed foods are recognized and that the translation proportion to correct for a weight reduction or increase is stored.
If successful, restart at the first step with each of the new codes of the ingredient foods, TDS foods or Read Across foods.
Marketshares link: try to find subtype codes, e.g. ‘xxx$*’ in the MarketShares table. In general, marketshares should sum to 100%. Foods with marketshares not summing to 100% are ignored in the analysis unless the checkbox Allow marketshares not summing to 100% is checked. This step is optional, see advanced settings. If successful, restart at step 1 with each of the new codes of the subtype foods.
Supertype link: try to find supertypes, e.g. ‘xxx$yyy’ is converted to ‘xxx’. This step is optional, see advanced settings if you want to use this. If successful, restart at step 1 with the new code of the supertype food.
Default processing factor: remove processing part (-xxx) of the code. If successful, restart at step 1 with the new code without processing part.
Substance dependent conversion¶
The original conversion algorithm contains two steps which are substance dependent. For each substance all food codes are supplied to the conversion algorithm and for each food code it is checked whether there is:
a concentration,
a processing type.
When a concentration is available for the food, this food is a modelled food (formerly known as food as measured). The food may be a food as eaten as such, like apple, or an ingredient of a food as eaten like tomato sauce on pizza which is converted to tomato. If concentrations are available, the food code is found and the conversion algorithm starts with converting the next food code. Otherwise, the conversion proceeds to the processing link (deprecated). Here, basically, processed foods are converted to an unprocessed food and processing type with corresponding processing factor. This processing step may be substance specific and, occasionally, this results in different conversion paths for different substances. This is undesirable behaviour and normally not the case (dependent on the supplied data in the food processing factor table). However, on rare occasions this might happen.
Find processing link (deprecated): Check whether the current food can be considered to be a processed variant (e.g., cooked or peeled) of another food.
Match processing factor: try to find the code in the processing factors table.
If successful, try to find the corresponding food translation proportion in the food recipes data to correct for a weight reduction or increase. Then, restart at the first step with the new code of the unprocessed food.
Warning: the find processing link (deprecated) step is not recommended and is currently maintained for backwards compatibility reasons only. Finding different conversions paths depending on the substance is undesirable behaviour.
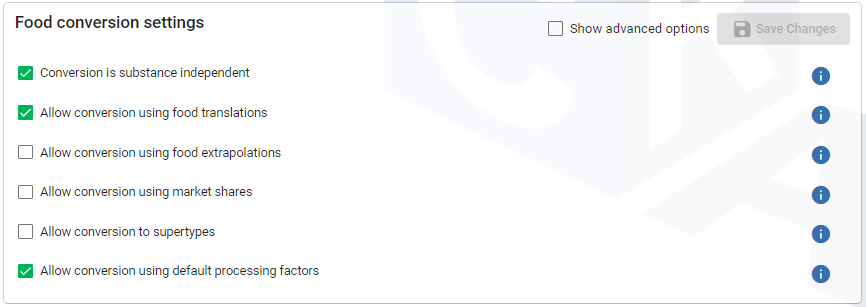
Figure 62 Default settings conversion.¶