Combining exposure sources
Individuals in a population are exposed to substances in sources like food (diet), plant protection products (PPPs) (in MCRA also referred as non-dietary exposures), dust, air and soil.
In a dietary exposure assessment, individuals generally have known values for properties such as age, sex, and body weight. The same applies to non-dietary exposures generated by BROWSE when individual IDs are linked to a known set of individuals—such as those from a dietary exposure assessment—or through the specification of survey properties related to age and/or sex. For exposures generated by the dust, air and soil modules, no explicit individuals or population are available. However, the exposure determinants used in these modules require information about age and/or sex. For example, dust exposure determinants such as ingestions rates, body exposure fractions, adherence amounts or availibility fractions are age- and/or sex specific. Therefore, in order to generate exposures, a population of individuals is required.
There are two options available for generating this set of individuals. Generate exposures based on:
individuals of the dietary survey e.g. see option Use dietary exposure,
a set of Simulated individuals (see e.g. generation method individuals).
Navigate to the air, dust and soil modules to specify which set of individuals for generating exposures should be used. This choice is independently for each exposure source.
Before aggregating exposures from different sources at the internal level, all exposures must first be combined at the external level for each individual. To begin, specify one exposure source, its corresponding set of individuals (simulated or dietary) will serve as the reference set. All other exposure sources will then be aligned with this reference.
It is clear that combining exposures at the external level becomes complex when different sets of individuals are used by the exposure generator in the air, dust and/or soil modules.
After specifying the reference source, there are three options available for matching an individual in the reference set with an individual from the other sources:
completely at random,
based on individual properties like age, sex (or other properties)
based on their individual ID,
For the first option, no additional information is required. Option 3, on the other hand, is the most restrictive, see also population alignment methods. This option is only applicable when each exposure source uses the same set of individuals. If the assessment includes a dietary source, all exposures from other source modules should be generated based on dietary individuals. If no dietary source is present, the appropriate choice is to use simulated individuals.
For the second option, individuals are matched based on specific properties. You can choose whether to use age and/or sex (male, female) or both as stratifying covariate. For age, matching can be done by specifying bins (e.g. 18 - 45 years) or by selecting individuals whose ages are closest to the age of the individual in the reference set. From the resulting subset, one individual is randomly sampled.
Non-dietary exposures
Originally, the non-dietary exposure module was developed to implement Bystanders, Residents, Operators and WorkerS Exposure models for plant protection products (BROWSE) software. Because this module has a different data format compared to the format of the dust, air and soil modules the method of matching individuals on the reference set is further explained.
In general, dietary and non-dietary surveys are independently taken (separated in space, location and time etc). Each survey contains a unique set of individuals and the only way to match individuals is completely at random or use stratifying covariates like age and or sex e.g. males, females between 18-45 years, children in the age of 0 to 5 years, etc.
Matching completely at random
For each individual in the dietary survey a random nondietary individual(day) from the nondietary surveys is sampled or vice versa. This option is also possible when surveys are identical.
Matching based on individual ID
When both dietary and non-dietary surveys contain identical individuals, individuals are matched based on their ID.
Matching based on individual properties
When dietary and non-dietary surveys are identical or partly identical, dietary and non-dietary exposures of indiviuals are matched based on the individual ID, e.g. for all Individuals of the food survey also a nondietary exposure is available or vice versa (method 3: individuals are matched based on the individual Id). Any nondietary exposure that does not correspond to an individual in the food survey will be ignored and vice versa (see Example 2). Occasionally, this is too restrictive and the assumption can be relaxed by specifying the individual ID in the nondietary survey as Id = General. Then, individual properties of the dietary individual should match the non-dietary survey properties.
When multiple non-dietary surveys are available, option Match individuals of multiple non-dietary surveys is relevant. When matching (correlation) is chosen, the exposure contributions of non-dietary individuals with identical Id in different surveys are combined and allocated to a dietary individual. When no correlation is chosen, the non-dietary exposures of randomly selected individuals from different surveys are combined and allocated to a dietary individual.
The user may also define demographic criteria for the assignment (for each source of non-dietary exposure) to indicate that those exposures are relevant only to a defined sub-population. Only those individuals in the food survey who meet the criteria of the non-dietary survey will be assigned non-dietary exposures from that source e.g. only males aged 18 to 65 (see Example 1). The simplest assessment consists of a single (deterministic) non-dietary exposure estimate which is assigned to all individuals in the food survey (Id = General). This case, and more complex possibilities are illustrated below using hypothetical examples (method 2: individuals are match based on individual properties).
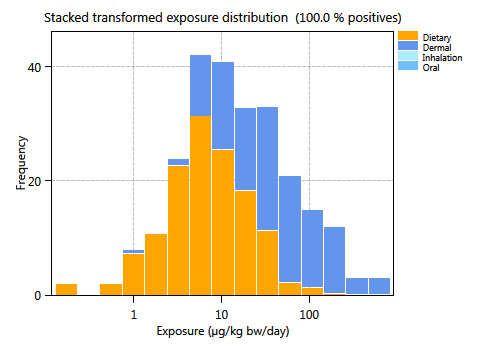
Figure 75 Exposure distributions for routes.
Example 1
Deterministic cumulative (multi-substance) non-dietary exposure input, adult male sub-population. Unmatched case.
idIndividual |
idNonDietarySurvey |
idSubstance |
Dermal |
Oral |
Inhalation |
|---|---|---|---|---|---|
General |
1 |
011003001 |
10 |
5 |
17 |
General |
1 |
011003002 |
34 |
20 |
18 |
General |
1 |
011003003 |
56 |
43 |
19 |
idNonDietarySurvey |
Description |
Location |
Date |
NonDietaryIntakeUnit |
|---|---|---|---|---|
1 |
BROWSE, acute, cumulative, operators |
York |
09/10/2012 |
\(\mu g/day\) |
idNonDietarySurvey |
PropertyIndividualName |
IndividualPropertyTextValue |
IndividualPropertyDoubleMinValue |
IndividualPropertyDoubleMaxValue |
|---|---|---|---|---|
1 |
Age |
18 |
65 |
|
1 |
Gender |
Male |
In this example, there are exposure values for multiple substances in Table 230 and the user has provided Table 232 which specifies that the non-dietary exposures given in survey number 1 relate to males aged 18 to 65.
When this assessment is performed, only those individuals whose property values fit the criteria in Table 232 will receive the non-dietary exposures in survey 1. The use of idIndividual = General indicates that this is the default exposure. All individuals in the dietary survey meeting the criteria receive all exposures given in the 3 rows, corresponding to 3 substances. The following should be noted:
Specify only one General entry in the non-dietary exposures table per substance x survey combination.
Property names and text properties must precisely match the values in the IndividualProperties and IndividualPropertyValues tables.
The minimum and maximum values for numeric properties are inclusive boundaries.
In the next example, all males aged 18 to 65 receive the given exposures of all three substances and the other members of the population receive no non-dietary exposure. Note that example 1 describes the unmatched case.
Example 2
Variability (but no uncertainty) in cumulative non-dietary exposure input (matched to dietary survey individuals).
idIndividual |
idNonDietarySurvey |
idSubstance |
Dermal |
Oral |
|---|---|---|---|---|
5432 |
1 |
011003001 |
10 |
5 |
5432 |
1 |
011003002 |
33 |
22 |
5433 |
1 |
011003001 |
12 |
7 |
5433 |
1 |
011003002 |
34 |
23 |
5434 |
1 |
011003001 |
18 |
9 |
5434 |
1 |
011003002 |
35 |
25 |
5435 |
1 |
011003001 |
10 |
5 |
5435 |
1 |
011003002 |
33 |
21 |
idNonDietarySurvey |
Description |
Location |
Date |
NonDietaryIntakeUnit |
|---|---|---|---|---|
1 |
BROWSE, acute, cumulative, operators |
York |
09/10/2012 |
\(\mu g/day\) |
In this example, the non-dietary exposures are specified explicitly for individuals in the dietary population. Switch ‘matching’ on to allow exposure variability to be specified at the individual level. Only four individuals are used. The values in the idIndividual column of Table 233 match those in the Individuals table (dietary population).
It is not mandatory to specify exposures for every individual in the population. Those not included will simply receive a zero non-dietary exposure, unless there is also a default exposure value (General row(s) in Table 233) and the individual matches the specified demographic criteria for the survey, as specified in Table 232. (In this example, a default exposure would apply to all individuals not listed in Table 233 because Table 232 has not been used).
There is variability between individuals in this example, but no uncertainty in exposure. Note that these data could also be used with matching switched off. This would be the same as treating the idIndividual values as generic individuals, so that each pair of exposure lines would be assigned at random to individuals meeting the criteria.
Example 3
Variability (no uncertainty) in cumulative non-dietary exposure input (unmatched individuals).
idIndividual |
idNonDietarySurvey |
idSubstance |
Dermal |
Oral |
Inhalation |
|---|---|---|---|---|---|
ND1 |
1 |
011003001 |
10 |
5 |
17 |
ND1 |
1 |
011003002 |
33 |
22 |
45 |
ND2 |
1 |
011003001 |
12 |
7 |
18 |
ND2 |
1 |
011003002 |
34 |
23 |
47 |
ND3 |
1 |
011003001 |
18 |
9 |
19 |
ND3 |
1 |
011003002 |
35 |
25 |
49 |
ND4 |
1 |
011003001 |
10 |
5 |
17 |
ND4 |
1 |
011003002 |
33 |
21 |
45 |
idNonDietarySurvey |
Description |
Location |
Date |
NonDietaryIntakeUnit |
|---|---|---|---|---|
1 |
BROWSE, acute, cumulative, operators |
York |
09/10/2012 |
\(\mu g/day\) |
idNonDietarySurvey |
PropertyIndividualName |
IndividualPropertyTextValue |
IndividualPropertyDoubleMinValue |
IndividualPropertyDoubleMaxValue |
|---|---|---|---|---|
1 |
Age |
50 |
65 |
|
1 |
Gender |
Female |
This example is similar to example 2, except that the values in the idIndividual column of Table 235 do not match those in the Individuals table. In this instance, ‘matching’ would not be an option, and the non-dietary exposures would be randomly assigned to individuals who meet the criteria in Table 237. (In fact for the same result rather than changing the values in the idIndividual column in Table 233 from the previous example may be used with matching switched off). Exposures in Table 235 will be recycled if the number of exposure rows is less than the number of dietary records with which to aggregate exposures.
Again, there is variability between individuals in this example, but no uncertainty in exposure.
By allowing generic idIndividual values in this way, correlations between different sources (within individual) can be accounted for even in the unmatched case. If the same idIndividual value is used in different surveys, then the corresponding exposure values will be kept together and assigned to an eligible individual as a combined exposure.
So for option matching switched of, it is relevant whether individuals are correlated or not. In the following example, two non-dietary surveys are available, per survey three individuals are specified.
idIndividual |
idNonDietarySurvey |
idSubstance |
Dermal |
Oral |
Inhalation |
|---|---|---|---|---|---|
ND0 |
1 |
011003001 |
10 |
5 |
17 |
ND1 |
1 |
011003001 |
23 |
22 |
45 |
ND2 |
1 |
011003001 |
12 |
7 |
18 |
ND0 |
2 |
011003001 |
34 |
23 |
47 |
ND3 |
2 |
011003001 |
18 |
9 |
19 |
ND4 |
2 |
011003001 |
33 |
16 |
35 |
When a correlation is applied, the non-dietary exposure for individual ND0 from survey 1 and 2 are combined and allocated to a dietary individual. For individual ND1, ND2, ND3 and ND4 just a single non-dietary exposure is found and allocated to a dietary individual.
When no correlation is applied, the exposure for individual ND0 from survey 1 is combined with one of the exposures of ND0, ND3 or ND4 from survey 2; exposure of ND1 from survey 1 is combined with one of the exposures of ND0, ND3 or ND4 from survey 2, etc.
When the intention is to sample just one exposure for a dietary individual, specify per survey different codes, e.g. ND1, ND2, ND3 for survey 1, ND4, ND5, ND6 for survey 2 and apply correlation, or specify 6 different individual codes and just one idNonDietarySurvey. Then, options with or without correlation are irrelevant and sampling results are identical.
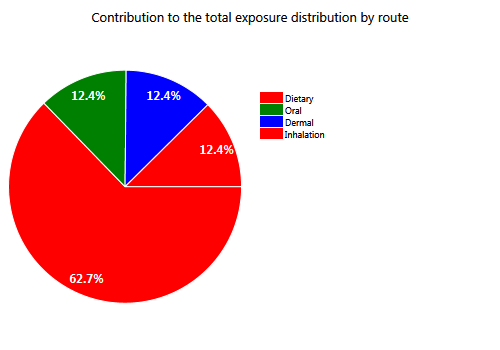
Figure 76 Contributions by route of the external exposure distributions.