Combining dietary and non-dietary exposures
If dietary and non-dietary exposures are available for the same individuals or individual-days, the non-dietary exposures can be matched to specific individuals of the food survey from which the dietary exposures are generated. More commonly, dietary and non-dietary exposures are available from separate surveys, in which case they can be randomly combined. If both dietary and non-dietary information is available for a known population of individuals, the user may select the matching option such that specific dietary and non-dietary estimates are aggregated for each individual in the food survey population. If matching is enabled, any non-dietary exposures that do not correspond to individuals from the food survey will be ignored (see Example 2), unless an individual is specified with id = General. In that case, the dietary individual should meet the criteria of the non-dietary survey, specified by the survey properties, to be assigned. If the non-dietary data relates instead to a population in which individuals have no corresponding records in the food survey (unmatched case), the user may choose to randomly assign the non-dietary exposures to the individuals from the food survey.
When multiple non-dietary surveys are available, the options with or without correlation are important (not relevant when matching is switched on). When correlation is chosen, the exposure contributions of non-dietary individuals with identical ids in different surveys are combined and allocated to a randomly selected dietary individual. When the correlation is not chosen, the non-dietary exposures of randomly selected individuals from different surveys are combined and allocated to a dietary individual.
The user may also define demographic criteria for the assignment (for each source of non-dietary exposure) to indicate that those exposures are relevant only to a defined sub-population. Only those individuals in the food survey who meet the criteria of the non-dietary survey will be assigned non-dietary exposures from that source e.g. only males aged 18 to 65 (see Example 1). The simplest assessment consists of a single (deterministic) non-dietary exposure estimate which is assigned to all individuals in the food survey (idIndividual = General). This case, and more complex possibilities are illustrated below using hypothetical examples.
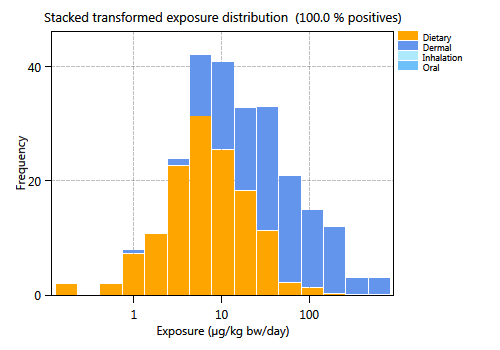
Figure 67 Aggregate exposure distributions.
Example 1
Deterministic cumulative (multi-substance) non-dietary exposure input, adult male sub-population. Unmatched case.
idIndividual |
idNonDietarySurvey |
idSubstance |
Dermal |
Oral |
Inhalation |
|---|---|---|---|---|---|
General |
1 |
011003001 |
10 |
5 |
17 |
General |
1 |
011003002 |
34 |
20 |
18 |
General |
1 |
011003002 |
56 |
43 |
19 |
idNonDietarySurvey |
Description |
Location |
Date |
NonDietaryIntakeUnit |
|---|---|---|---|---|
1 |
BROWSE, acute, cumulative, operators |
York |
09/10/2012 |
\(\mu g/day\) |
idNonDietarySurvey |
PropertyIndividualName |
IndividualPropertyTextValue |
IndividualPropertyDoubleMinValue |
IndividualPropertyDoubleMaxValue |
|---|---|---|---|---|
1 |
Age |
18 |
65 |
|
1 |
Gender |
Male |
In this example, there are exposure values for multiple substances in Table 140 and the user has provided Table 142 which specifies that the non-dietary exposures given in survey number 1 relate to males aged 18 to 65.
When this assessment is performed, only those individuals whose property values fit the criteria in Table 142 will receive the non-dietary exposures in survey 1. The use of idIndividual = General indicates that this is the default exposure. All individuals in the dietary survey meeting the criteria receive all exposures given in the 3 rows, corresponding to 3 substances. The following should be noted:
There should only ever be one General entry in the dietary exposures table per substance, survey combination.
The property names and the values of any text properties must precisely match those given in the IndividualProperties and IndividualPropertyValues tables for this to work.
The minimum and maximum values for numeric properties are both inclusive boundaries.
So in this example, all males aged 18 to 65 will receive the given exposures of all three substances and the other members of the population will receive no non-dietary exposure. Note that example 1 describes the unmatched case.
Example 2
Variability (but no uncertainty) in cumulative non-dietary exposure input (matched to dietary survey individuals).
idIndividual |
idNonDietarySurvey |
idSubstance |
Dermal |
Oral |
|---|---|---|---|---|
5432 |
1 |
011003001 |
10 |
5 |
5432 |
1 |
011003002 |
33 |
22 |
5433 |
1 |
011003001 |
12 |
7 |
5433 |
1 |
011003002 |
34 |
23 |
5434 |
1 |
011003001 |
18 |
9 |
5434 |
1 |
011003002 |
35 |
25 |
5435 |
1 |
011003001 |
10 |
5 |
5435 |
1 |
011003002 |
33 |
21 |
idNonDietarySurvey |
Description |
Location |
Date |
NonDietaryIntakeUnit |
|---|---|---|---|---|
1 |
BROWSE, acute, cumulative, operators |
York |
09/10/2012 |
\(\mu g/day\) |
In this example, the non-dietary exposures are being specified explicitly for individuals in the dietary population. Switch ‘matching’ on to allow exposure variability to be specified at the individual level. For the purposes of illustration, the population is extremely small, consisting of only four individuals. The values in the idIndividual column of Table 143 match those in the Individuals table (dietary population).
It is not mandatory to specify exposures for every individual in the population. Those not included will simply receive a zero non-dietary exposure, unless there is also a default exposure value (General row(s) in Table 143) and the individual matches the specified demographic criteria for the survey, as specified in Table 142. (In this example, a default exposure would apply to all individuals not listed in Table 143 because Table 142 has not been used).
There is variability between individuals in this example, but no uncertainty in exposure. Note that these data could also be used with matching switched off. This would be the same as treating the idIndividual values as generic individuals, so that each pair of exposure lines would be assigned at random to individuals meeting the criteria.
Example 3
Variability (no uncertainty) in cumulative non-dietary exposure input (unmatched individuals).
idIndividual |
idNonDietarySurvey |
idSubstance |
Dermal |
Oral |
Inhalation |
|---|---|---|---|---|---|
ND1 |
1 |
011003001 |
10 |
5 |
17 |
ND1 |
1 |
011003002 |
33 |
22 |
45 |
ND2 |
1 |
011003001 |
12 |
7 |
18 |
ND2 |
1 |
011003002 |
34 |
23 |
47 |
ND3 |
1 |
011003001 |
18 |
9 |
19 |
ND3 |
1 |
011003002 |
35 |
25 |
49 |
ND4 |
1 |
011003001 |
10 |
5 |
17 |
ND4 |
1 |
011003002 |
33 |
21 |
45 |
idNonDietarySurvey |
Description |
Location |
Date |
NonDietaryIntakeUnit |
|---|---|---|---|---|
1 |
BROWSE, acute, cumulative, operators |
York |
09/10/2012 |
\(\mu g/day\) |
idNonDietarySurvey |
PropertyIndividualName |
IndividualPropertyTextValue |
IndividualPropertyDoubleMinValue |
IndividualPropertyDoubleMaxValue |
|---|---|---|---|---|
1 |
Age |
50 |
65 |
|
1 |
Gender |
Female |
This example is similar to example 2, except that the values in the idIndividual column of Table 145 do not match those in the Individuals table. In this instance, ‘matching’ would not be an option, and the non-dietary exposures would be randomly assigned to individuals who meet the criteria in Table 147. (In fact for the same result rather than changing the values in the idIndividual column in Table 143 from the previous example may be used with matching switched off). Exposures in Table 145 will be recycled if the number of exposure rows is less than the number of dietary records with which to aggregate exposures.
Again, there is variability between individuals in this example, but no uncertainty in exposure.
By allowing generic idIndividual values in this way, correlations between different sources (within individual) can be accounted for even in the unmatched case. If the same idIndividual value is used in different surveys, then the corresponding exposure values will be kept together and assigned to an eligible individual as a combined exposure.
So for option matching switched of, it is relevant whether individuals are correlated or not. In the following example, two non-dietary surveys are available, per survey three individuals are specified.
idIndividual |
idNonDietarySurvey |
idSubstance |
Dermal |
Oral |
Inhalation |
|---|---|---|---|---|---|
ND0 |
1 |
011003001 |
10 |
5 |
17 |
ND1 |
1 |
011003001 |
23 |
22 |
45 |
ND2 |
1 |
011003001 |
12 |
7 |
18 |
ND0 |
1 |
011003001 |
34 |
23 |
47 |
ND3 |
1 |
011003001 |
18 |
9 |
19 |
ND4 |
1 |
011003001 |
33 |
16 |
35 |
When a correlation is applied, the non-dietary exposure for individual ND0 from survey 1 and 2 are combined and allocated to a dietary individual. For individual ND1, ND2, ND3 and ND4 just a single non-dietary exposure is found and allocated to a dietary individual.
When no correlation is applied, the exposure for individual ND0 from survey 1 is combined with one of the exposures of ND0, ND3 or ND4 from survey 2; exposure of ND1 from survey 1 is combined with one of the exposures of ND0, ND3 or ND4 from survey 2, etc.
When the intention is to sample just one exposure for a dietary individual, specify per survey different codes, e.g. ND1, ND2, ND3 for survey 1, ND4, ND5, ND6 for survey 2 and apply correlation, or specify 6 different individual codes and just one idNonDietarySurvey. Then, options with or without correlation are irrelevant and sampling results are identical no matter which option is chosen.
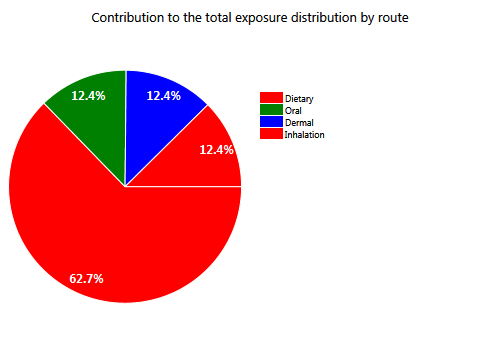
Figure 68 Contributions by route to aggregate exposure distributions.